ByteDance
OmniHuman
OmniHuman 是字节跳动(ByteDance)的音频驱动 OmniHuman 口型同步模型:输入一张静态肖像和一段音频,即可生成带有逐帧精准唇部运动、面部表情和自然头部动作的说话头部视频。OmniHuman AI 系列(v1 与 v1.5)由字节跳动智能创作团队打造,是 2026 年 Martini 上口型同步最精准的视频模型之一。
OmniHuman 是字节跳动的音频驱动肖像动画模型,可将单张照片配合语音轨道转化为口型同步的说话头部视频。ByteDance OmniHuman 负责完整表演:它读取音频波形,驱动同步的唇部运动、眨眼、微表情和头部摇摆,让画面人物看起来真正在说出所给文字。1.0 版本可从正面照片配合语音音频生成稳定的 OmniHuman 口型同步和头部运动。1.5 版本(OmniHuman-1.5)提升了口型同步精度,支持更广泛的肖像风格(包括插画和风格化面孔),并生成更自然的头部动作和更长的稳定片段。在 Martini 上,两个版本都与文本转语音模型位于同一节点式画布中,因此你可以在浏览器内端到端运行 文本 -> 语音 -> OmniHuman 动画。相比 Kling AI Avatar 和 HeyGen 类数字人工具,OmniHuman 专为从单张图像实现纯粹的口型同步保真度而设计,而非依赖固定头像库,因此当你需要让任意人脸开口说话时,它是首选。扇出功能让你可以同时将相同音频接入 OmniHuman、Kling AI Avatar 和 Hailuo Speech-02,并在版本托盘中保留最佳结果。
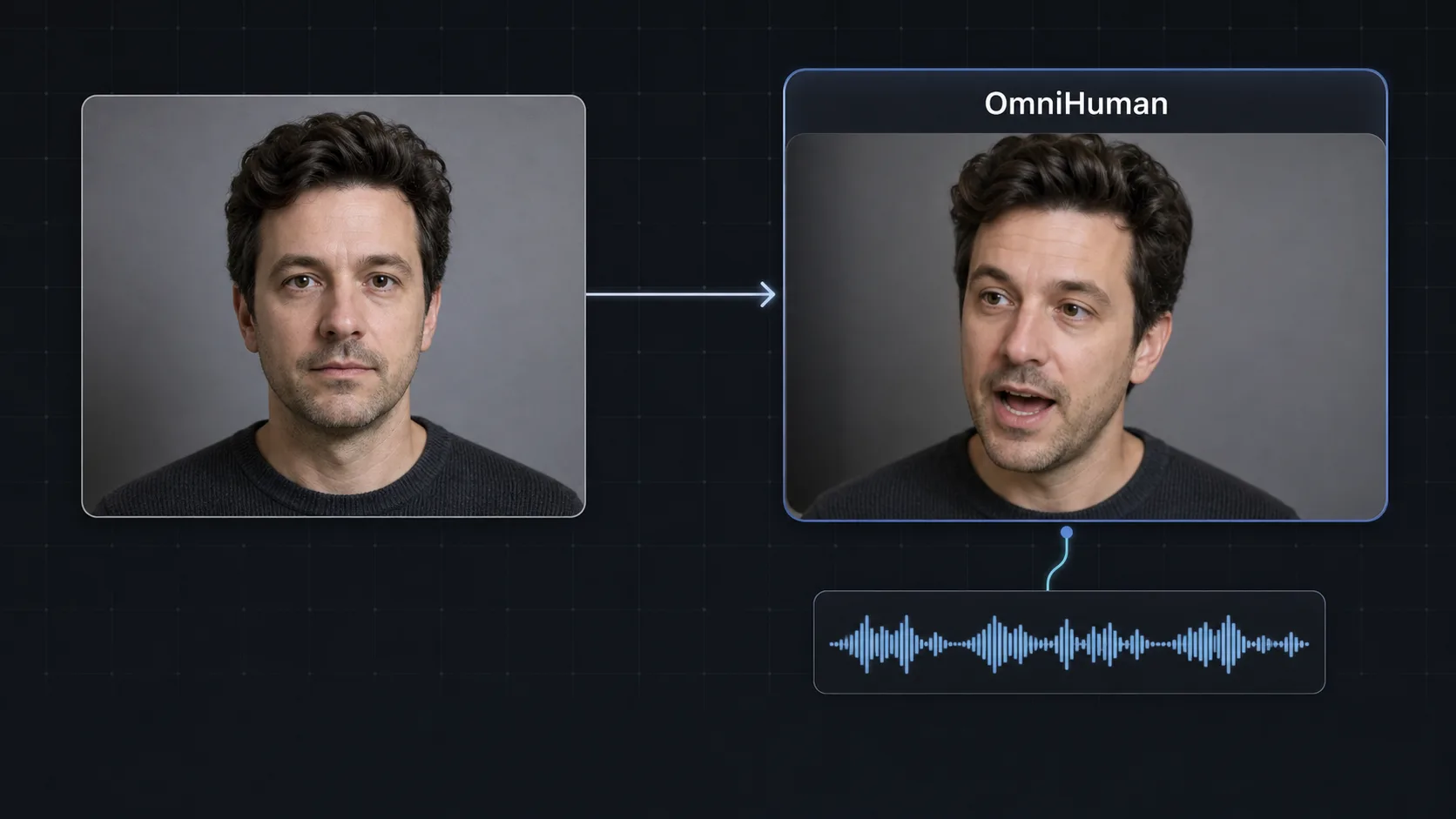
OmniHuman 变体
| 变体 | 说明 |
|---|---|
| OmniHuman v1 | 音频驱动的肖像动画,支持口型同步、表情和头部动作。 |
| OmniHuman v1.5 | 改进的口型同步精度,更好地支持多样化肖像风格。 |
支持的功能
支持的宽高比
最适合
- 说话头部视频和虚拟主持人
- 将任意肖像与配音或歌曲进行口型同步
- 播客和旁白可视化
- 内容创作者虚拟形象动画
- 音频驱动的角色表演
优势
- 业界领先的 OmniHuman 口型同步,时间节奏自然且逐帧精准
- 仅凭音频即可生成丰富的面部表情、眨眼和头部动作
- v1.5 支持插画、风格化和非正面肖像风格
- 可驱动任意上传的人脸——无需固定头像库
- 与 TTS 模型无缝衔接,实现端到端说话头部视频制作
局限性
- 需要音频输入——不支持文本生成视频
- 清晰、光线充足的正面肖像效果最佳
- 单人场景,不适合群体画面
使用技巧
在 Martini 上使用 OmniHuman
在 Martini 的无限画布上将 OmniHuman 与其他 AI 模型连接使用。无需 GPU,免费开始。
免费开始常见问题
OmniHuman 是什么?由谁开发?
OmniHuman 是字节跳动(TikTok 和 CapCut 的母公司)开发的音频驱动肖像动画模型。它接收一张静态照片和一段音频,生成带有同步唇部运动、表情和头部动作的说话头部视频。在 Martini 上,你可以直接在画布中运行 OmniHuman v1 和 v1.5,无需本地安装或 GPU。
OmniHuman 是字节跳动的吗?
是的。OmniHuman 由字节跳动开发,出自其智能创作团队,于 2025 年初首次发布。OmniHuman AI 系列(v1 和 OmniHuman-1.5)专注于将一张肖像图像配合语音音频转化为口型同步的说话头部视频,Martini 同时托管这两个版本以及 50 多个其他 AI 视频和音频模型。
OmniHuman 支持口型同步吗?
支持——OmniHuman 口型同步是该模型的核心能力。它读取所提供的音频波形,驱动逐帧精准的唇部运动、眨眼和头部动作,让肖像看起来真正在说话。v1.5 进一步提升了口型同步精度,并能处理 v1 难以应对的插画和风格化面孔。
OmniHuman 需要什么输入?
OmniHuman 需要两个输入:一张肖像图像(清晰、光线充足的正面照片效果最佳)和一段音频,如语音、旁白或歌声。它没有文本生成视频模式——音频驱动整个表演。在 Martini 上,你可以先用文本转语音模型生成音频,再直接接入 OmniHuman 节点。
OmniHuman 与 Kling AI Avatar 有何不同?
OmniHuman 和 Kling AI Avatar 都能将肖像配合音频转化为说话头像,但 OmniHuman 专为从任意上传的人脸实现纯粹的口型同步保真度而设计,而 Kling AI Avatar 提供针对逼真主持人调优的标准和专业质量档位。在 Martini 上你无需取舍——扇出功能让你可以同时在 OmniHuman、Kling AI Avatar 和 Hailuo 上运行相同音频,并保留最佳结果。
可以用 OmniHuman 从照片制作说话头部视频吗?
可以。上传一张正面肖像,提供或生成配音,OmniHuman 即可将面部动画化为带有同步口型和自然头部运动的说话头部视频。这使其非常适合虚拟主持人、内容创作者形象、播客可视化和旁白。在 Martini 上将其与文本转语音节点结合,即可实现完整的 文本 -> 语音 -> 说话头像 流程。
OmniHuman 在 Martini 上的费用是多少?
OmniHuman 运行于 Martini 的积分系统,因此你从订阅额度或钱包充值中按次生成付费,而非单独的按模型订阅。截至 2026 年,你可以在同一画布上将相同音频扇出到 OmniHuman v1、OmniHuman-1.5 和竞品数字人模型,仅保留并关注你最终采用的结果。