ByteDance
OmniHuman
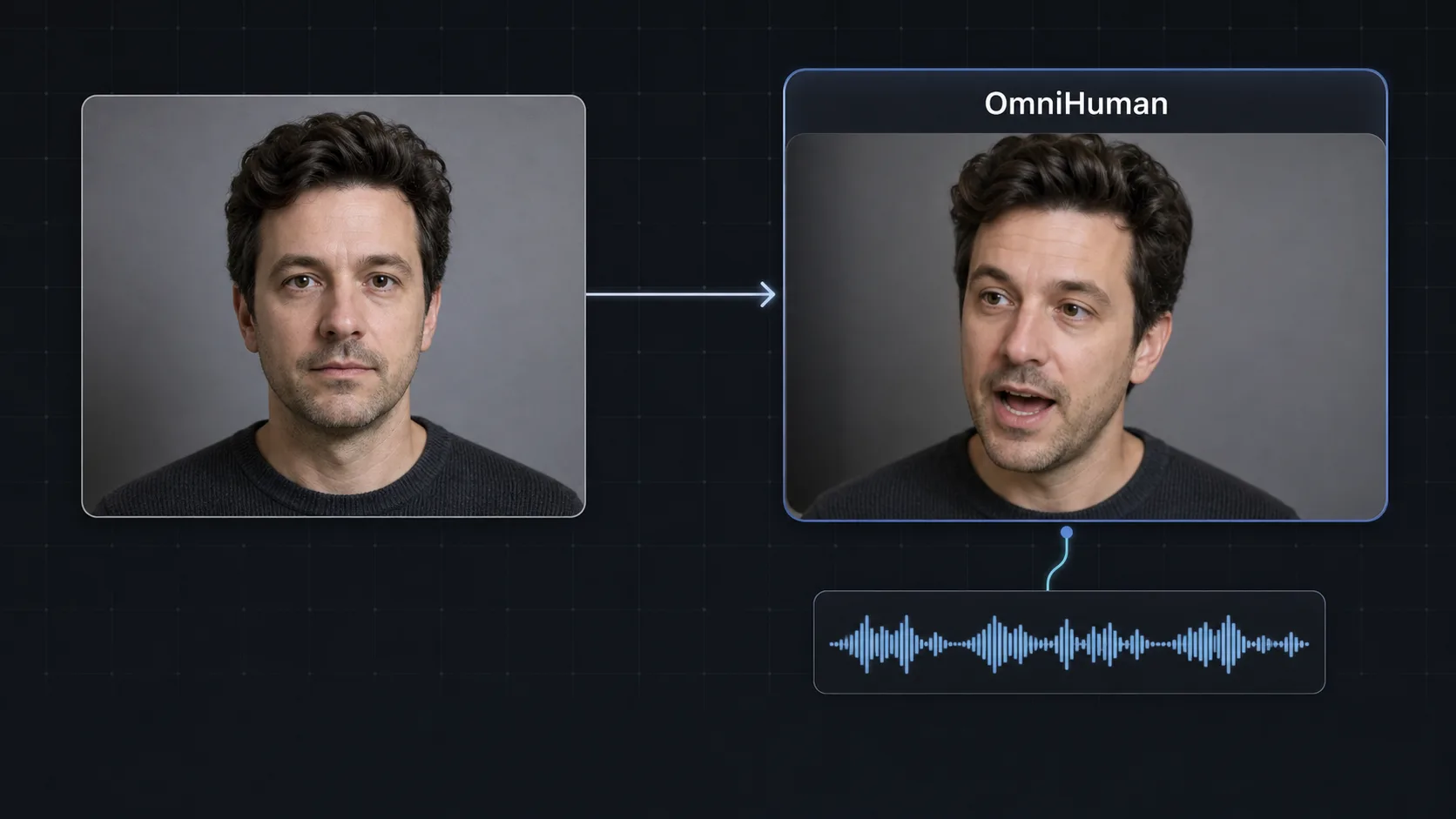
OmniHuman is ByteDance's audio-driven OmniHuman lip sync model: feed it one still portrait and an audio track, and it returns a talking-head video with frame-accurate lip movements, facial expressions, and natural head gestures. Built by ByteDance Intelligent Creation, the OmniHuman AI family (v1 and v1.5) is one of the most accurate open lip-sync video models available on Martini in 2026.
OmniHuman is a ByteDance audio-driven portrait animation model that converts a single photo plus a speech track into a lip-synced talking-head video. ByteDance OmniHuman handles the full performance: it reads the audio waveform and drives synchronized lip movements, blinks, micro-expressions, and head sway, so the subject looks like it is genuinely speaking the supplied words. Version 1.0 delivers solid OmniHuman lip sync and head motion from a front-facing photo paired with speech audio. Version 1.5 (OmniHuman-1.5) raises lip-sync accuracy, handles a wider range of portrait styles including illustrated and stylized faces, and produces more natural head gestures and longer stable takes. On Martini both versions sit on the same node-based canvas as text-to-speech models, so you can run text -> speech -> OmniHuman animation end to end without leaving the browser. Versus Kling AI Avatar and HeyGen-style avatar tools, OmniHuman is purpose-built for raw lip-sync fidelity from a single image rather than a fixed avatar library, which makes it the go-to choice when you need any face to talk. Fan-out lets you wire the same audio into OmniHuman, Kling AI Avatar, and Hailuo Speech-02 at once and keep the best take in the version tray.
OmniHuman Variants
| Variant | Description |
|---|---|
| OmniHuman v1 | Audio-driven portrait animation with lip sync, expressions, and head gestures. |
| OmniHuman v1.5 | Improved lip-sync accuracy with better handling of diverse portrait styles. |
Capabilities
Supported Aspect Ratios
Best For
- Talking-head videos and virtual presenters
- Lip-syncing any portrait to a voiceover or song
- Podcast and narration visualizations
- Content creator avatar animation
- Audio-driven character performance
Strengths
- Class-leading OmniHuman lip sync with natural, frame-accurate timing
- Expressive facial expressions, blinks, and head gestures from audio alone
- v1.5 handles illustrated, stylized, and non-frontal portrait styles
- Animates any uploaded face — no fixed avatar library required
- Chains seamlessly with TTS models for end-to-end talking-head production
Limitations
- Requires audio input — no text-to-video mode
- Best results with clear, well-lit front-facing portraits
- Single-person focus, not suited for group scenes
Tips & Best Practices
Use OmniHuman on Martini
Connect OmniHuman with other AI models on Martini's infinite canvas. No GPU required — start free.
Get Started FreeFrequently Asked Questions
What is OmniHuman and who made it?
OmniHuman is an audio-driven portrait animation model made by ByteDance (the company behind TikTok and CapCut). It takes a single still photo and an audio track and generates a talking-head video with synchronized lip movements, expressions, and head motion. On Martini you can run OmniHuman v1 and v1.5 directly on the canvas without any local install or GPU.
Is OmniHuman from ByteDance?
Yes. OmniHuman is built by ByteDance, developed by its Intelligent Creation team and first published in early 2025. The OmniHuman AI family (v1 and OmniHuman-1.5) focuses on turning one portrait image plus speech audio into a lip-synced talking-head video, and Martini hosts both versions alongside 50+ other AI video and audio models.
Does OmniHuman do lip sync?
Yes — OmniHuman lip sync is the model's core capability. It reads the supplied audio waveform and drives frame-accurate lip movements, blinks, and head gestures so the portrait looks like it is genuinely speaking. v1.5 improves lip-sync accuracy further and handles illustrated and stylized faces that v1 struggles with.
What input does OmniHuman need?
OmniHuman needs two inputs: one portrait image (a clear, well-lit, front-facing photo works best) and an audio track such as speech, narration, or singing. It has no text-to-video mode — the audio drives the entire performance. On Martini you can generate that audio first with a text-to-speech model and wire it straight into the OmniHuman node.
How is OmniHuman different from Kling AI Avatar?
OmniHuman and Kling AI Avatar both turn a portrait plus audio into a talking head, but OmniHuman is purpose-built for raw lip-sync fidelity from any uploaded face, while Kling AI Avatar offers Standard and Pro quality tiers tuned for lifelike presenters. On Martini you do not have to choose — fan-out lets you run the same audio across OmniHuman, Kling AI Avatar, and Hailuo simultaneously and keep the best take.
Can I make a talking-head video from a photo with OmniHuman?
Yes. Upload a front-facing portrait, supply or generate a voiceover, and OmniHuman animates the face into a talking-head video with synced lips and natural head movement. This makes it ideal for virtual presenters, content-creator avatars, podcast visualizations, and narration. Combine it with a text-to-speech node on Martini for a full text -> speech -> talking-head pipeline.
How much does OmniHuman cost on Martini?
OmniHuman runs on Martini's credit system, so you pay per generation from your subscription quota or wallet top-up rather than a separate per-model subscription. As of 2026, you can fan the same audio across OmniHuman v1, OmniHuman-1.5, and rival avatar models on one canvas and only keep (and pay attention to) the take you ship.